C/C++:关于文件I/O
读写文件,控制台交互,这是C/C++永恒的主题之一。
引子
每个人都知道至少一种输入、输出的编写方式。如果你是一个基础扎实的编码者,或许你知道两种甚至更多。这对于编写自己的程序似乎是远远足够了。
但在上周,在我查询关于如何在C/C++里实现$ ls -a | grep txt时,我遇到了一些挫折。如你所见,这里需要一些重定向和管道的知识。我查到了许多有效的代码案例,但让我困惑的是,它们的风格并不一致,有的使用了fopen(),有的使用了dup(),有的使用printf(),有的使用write()。我确信其中的相当一部分是可以彼此替代的,但却无从下手。
因此,我重新梳理了以下关于文件I/O的一些核心命题。你恐怕不会读到太多时髦的东西,但我相信这些知识能帮你更好地理解一些已经存在了很久的东西。
在下文,我试图回答以下几个问题:
- 什么是文件描述符(为什么这个非负整数可以代表一个文件)
- 用文件描述符管理文件,和用文件指针有什么区别
- 什么是系统I/O和标准I/O(你用过
dup()吗) - 为什么不要混合使用系统I/O和标准I/O
- 缓冲区会搞出什么乱子(C/C++给我上的第一课:最简单的功能需要最深刻的理解)
- 标准输入/输出/错误是什么(是键盘输入、屏幕输出)
- 怎么在C/C++里面重定向标准流输入/输出(我知道,很多作业需要这个)
现在,让我们从这一行代码开始吧。
1 | |
打开文件表(open file table)
为了理解文件描述符(file descriptor)的概念,让我们先回顾一下操作系统和文件系统(Virtual File System, VFS)的内容。
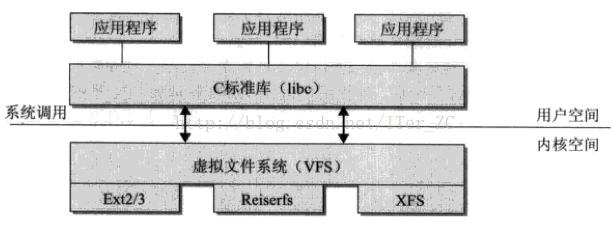
我们知道,文件存储在硬盘上。应用程序对文件访问时,先向内核提供文件的路径(如/home/code/hello.c),然后由内核从根目录开始,一级一级解析路径、搜索目录,直到最终定位到文件,得到文件的相关信息,比如其存储与硬盘的何处。
遍历文件树的这个开销是不可忽略的,如果每一次读写文件都要从头找到它,也未免太过麻烦了。因此,linux等操作系统内核维护一个打开文件表(open-file-table),这个列表里存放了所有目前打开的文件的信息,统一管理。
考虑到文件的访问者是进程,而多个进程可能同时对同一个文件进行不同位置的读写,打开文件表最终采用了两级内部表的设计。文件打开表分为了每个进程独有的一个进程表(用户打开文件表),和整个系统共用的一个系统表(系统打开文件表)。进程表的每个条目相应地指向系统表的条目,而系统表的条目再指向文件的具体位置。两级内部表使得多个进程打开同一个文件时,重叠部分不必反复存储,因而开销增长变得很小。
从进程的角度看,在显式地打开文件后,对文件进行读写操作时,直接通过自己进程表的索引(index)来指定文件。而进程表的索引,这个非负的整数,就是**文件描述符(file descriptor, fd)**。
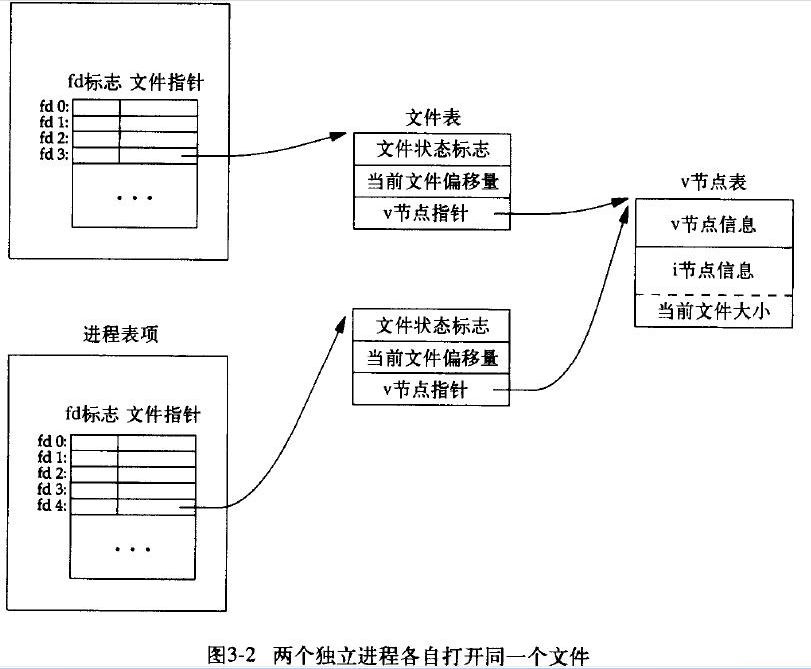
读写一个文件所需要的信息被分级存储在了系统表和进程表条目上。系统表条目中,存储了与进程无关的信息,例如文件在磁盘上的位置、访问日期和文件大小等,并维护一个**打开计数(open count)**。而进程表条目中,存储了进程对文件的使用信息,如文件指针、访问权限等。
更具体而言,进程对文件的访问流程如下:
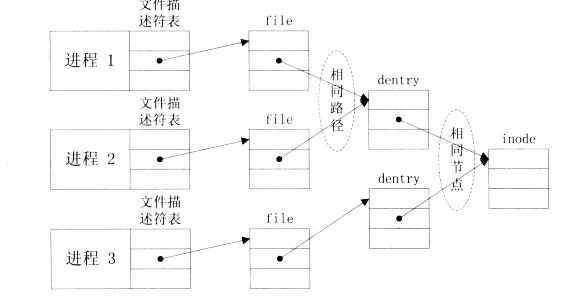
进程表条目、系统表条目、目录项和inode的概念概括如下:
进程表条目(文件描述符)
文件描述符是一个进程级的概念,因此,脱离进程去考虑它是无意义的。它的存在地位类似于一个文件指针
FILE *,不同的文件描述符也可能指向同一个文件。系统表条目
系统表条目指示一个被打开的文件。它的数据结构里面存储了打开计数,也就是有多少个进程正打开了该文件。因此,系统表条目的存在说明该文件被至少一个进程打开,可能有读可能有写。它的里面直接存储inode的链接,而不存储目录下的链接,但inode的查找需要通过遍历目录项来得到。因此,对于已打开文件,其路径信息可以认为是被抹去的。
目录项(dentry)
目录项是文件树的组成节点,所有路径查找都是通过目录项的逐级跳转实现的。其存有父子节点链接,文件名和inode链接等。解析路径查找文件的过程便是在目录项上逐级跳转,但在找到了文件之后,我们便不再关心它了。也就是说,文件的编辑和移动其实是分离的,你不能把移动文件视作某一种对文件内容的编辑。
inode
inode存储了字节数、UserID、GroupID、读写执行权限、时间戳等文件的元信息,和指向存有文件数据的block的链接。inode号码与文件名相分离,也就是说,inode不知情文件的路径、文件名等信息,不关心文件在文件树中的位置。不考虑硬链接的情况下,可以认为inode号就是文件的唯一标识。再四舍五入一下,可以近似认为inode就是文件本身(毕竟所有对文件的操作都绕不开inode)。
文件描述符(file descriptor)
以上是操作系统层面对文件描述符的理解。但在实际应用中,我们更关心如何在软件开发层面理解它。
正如上文所说,在unix中,文件在进程中通常抽象化表示为一个文件描述符。
文件描述符是一个非零整数,用以标明每一个被进程所打开的文件。每次打开文件时,按照升序为其分配未被占用的非零整数。例如,第一个打开的文件分配为0,第二个分配为1,若为0的文件被关闭,则下一个打开的文件分配获得的文件描述符则为0。
- 同一个进程内,不同的文件描述符也可能指向同一个文件
- 不同进程间,同一个文件描述符可能指向不同文件
因为文件描述符是一个进程自己的进程表的序号,所以对于不同的进程,比较它们的文件描述符没有什么意义。但事实上,它们也可以跨进程地发挥用处,因为在进程fork()之后,子进程会复制父进程的进程表,父进程的文件描述符都会被继承,且指向相同的文件(系统表的相同位置)。这也称作父子进程间的文件共享。
而在同一个进程内,如果你多次打开同一个文件,那么你将得到多个不同的文件描述符,而它们指向同一个文件(系统表的相同位置)。不同的文件描述符之间不会彼此影响,哪怕它们事实上指向同一文件,你也需要将它们一一关闭,而不是关闭其中一个即可,即“内核的归内核管,程序员的归程序员管”。
总之,你其实不关心它们是否指向同一个文件。
标准I/O与系统I/O
对文件描述符的操作是管理文件的基本方式,但却不是我们熟悉的方式。任何一个学过C的人都不会对下面的代码感到陌生。
1 | |
而对这种下面的这段代码,恐怕没有那么熟悉。(也有可能,你是一个酷爱管理所有底层细节的C语言专家)
1 | |
(当我第一次看到int fd时,我确实被搞糊涂了,现在你可以知道它是一个文件描述符)
基于文件指针FILE *的I/O(或者标准I/O),实际上是C语言对基于文件描述符的I/O(或者系统I/O)的一层封装,用fprintf()、fscanf()等替代read()和write()。每个FILE对象中存储了一个文件描述符。二者之间可以进行自由的相互转换。大多数时候它们是一一对应的关系,只要你不捣乱。
1 | |
标准I/O和系统I/O都是对I/O的操作不同风格的管理,简要对比如下:
| 标准I/O | 系统I/O | |
|---|---|---|
| 头文件 | stdio.h |
io.h |
| 文件表示 | FILE * (文件指针) |
int (文件描述符) |
| 打开文件 | fopen() |
open() |
| 关闭文件 | fclose() |
close() |
| 常用写出 | fprintf() |
write() |
| 常用读入 | fscanf() |
read() |
| 标准输入 | stdin |
STDIN_FILENO (即0) |
| 标准输出 | stdout |
STDOUT_FILENO (即1) |
| 标准错误 | stderr |
STDOUT_FILENO (即2) |
| 特点 | 流处理,有缓冲区 | 更低级些 |
标准I/O除了封装了各个数据类型与字符串之间的转换(也就是%d,%f那些),还使用了缓冲技术,当数据写入时并没有立即把数据交给内核,而是先存放在缓冲区(buffer)中,当缓冲区满时,会一次性把缓冲中的数据交给内核写到文件中,这样就减少内核态与用户态的切换次数。而系统I/O每写一次数据就要进入一次内核态,这样就浪费了大量时间进行内核态与用户态的切换,因此用时更长。
系统I/O则是操作系统双手的延申,可以实现字节级别的数据管理,即时性高,它比较适合底层开发。而缓冲区策略则更适合日常的应用场景。
缓冲区的潜在问题
缓冲区的设计在大部分日常场景下都是高效的,但它存在一些潜在的问题。
缓冲区机制虽然试图表现得透明,然而它并不是透明的。就像缓存(cache)会因更新不及时导致读到的数据不符预期,缓冲不及时也会导致错误的(甚至是匪夷所思的)写出结果。
以下是一个例子:
1 | |
1.out中的输出如下:
1 | |
可以看到,我们的程序只进行了一次写,却产生了两份输出。究其原因,是因为程序在执行完第8行后,并没有真正把结果写入1.out中,而是将其放入了缓冲区,等进程结束时才统一写入。然而,fork()产生的子进程拷贝了父进程的缓冲区和文件描述符,因此,子进程和父进程结束时,分别进行了一次缓存更新,总共产生了两次写入。
针对不同的场景,标准I/O预设了三种缓冲区,分别是全缓冲、行缓冲和无缓冲。
- 全缓冲:仅当I/O缓冲区被填满,或者文件被关闭,或进程结束时,才刷新缓冲区,进行实际I/O操作。也可以执行
fflush()手动刷新。读写一般文件默认为全缓冲。 - 行缓冲:标准输入、标准输出流都是采用行缓冲。也就是每次换行时进行实际I/O操作。
- 无缓存:标准错误流就是采用无缓冲。第一时间进行I/O。(正如系统I/O)
它们具有不同的更新及时性。更新的越及时,I/O负担越大,有时是不必要的;而更新的越不及时,越有可能通过合并I/O提升效率,但有可能产生预期外的表现。当然,你也可以手动更改指定文件的缓冲区类型。
正是因为标准I/O对一般文件的读写默认为全缓冲,因此会出现这种情况:程序写入日志时,外部打开文件总是看不见更新,得等程序关闭该文件时,或者程序执行完毕时,才能拿到输出。
正如你所见,你应当对缓冲区问题保持一定的警惕。这可不是什么闭着眼睛用就能发挥奇效的东西,当问题发生时,你和计算机之间,总会有一个在自作聪明。
基于类似的理由,当你在混合使用printf()和write()时,二者的输出顺序与代码的执行顺序是否一致,会取决于你将其重定向至一个文件或是终端。这很有可能导致“bug仅出现于生产环境下”的欺骗性灾难。
1 | |
1 | |
我会向你展示更多例子,证明标准I/O和系统I/O的混合使用不会是一个好的主意。
混合使用标准I/O与系统I/O的潜在问题
尽管文件描述符和文件指针之间可以进行自由的相互转换,也可以创建多个文件指针指向同一个文件描述符,将二者混合使用,不过很少这么做。
一方面是因为文件描述符在通过open()创建时已经制定了读写类型(只读、只写、可读写等),而在使用fdopen()转换时需要指定该文件指针的流形态(mode),此形态必须和原先文件描述符的读写模式相同,否则将会转换失败。
1 | |
(还好,你至少能知道它失败了)
另一方面是因为,当多个文件指针指向同一个文件描述符时,调用了fclose()后,相应的文件描述符fd也会被关闭,导致其他文件指针无效。
如果需要多个文件指针指向同一个文件,且分别管理生命周期,正确的使用方式应该是:用dup()复制文件描述符,确保文件描述符和文件指针是一一对应的关系。
总之,应避免二者的混合使用。
Note that mixing use of FILEs and raw file descriptors canproduce unexpected results and should generally be avoided. (Forthe masochistic among you: POSIX.1, section 8.2.3, describes indetail how this interaction is supposed to work.) A general ruleis that file descriptors are handled in the kernel, while stdiois just a library. This means for example, that after anexec(3), the child inherits all open file descriptors, but allold streams have become inaccessible.
stdin(3) — Linux manual page
来自Manual的警告
标准输入(stdin),标准输出(stdout),标准错误(stderr)
除了对硬盘里文件的读写,还有一种最常见的读写,便是与程序员通过终端(terminal)画面和键盘进行的交互。程序读取终端里键入的一行内容,作为输入,然后将各种信息打印到终端画面上,作为输出。这便是我们熟悉的标准输入、输出。
在正常情况下,每个 UNIX 程序在启动时都会为其打开三个流,一个用于输入,一个用于输出,一个用于打印诊断或错误消息。这些通常附加到用户的终端),但可能会引用文件或其他设备,具体取决于父进程选择设置的内容。
stdin(3) — Linux manual page
也就是说,对于每个程序(进程),在开始运行时都获得了默认的的标准输入(0),标准输出(1),标准错误(2)的文件描述符。操作系统贴心地将标准输入、标准输出、标准错误被抽象成了文件,将标准输入、输出文件与终端界面、键盘相连接,使得程序员可以将对它们的读写等价地理解为对文件的读写。
| 标准I/O | 系统I/O | |
|---|---|---|
| 文件表示 | FILE * (文件指针) |
int (文件描述符) |
| 标准输入 | stdin |
STDIN_FILENO (即0) |
| 标准输出 | stdout |
STDOUT_FILENO (即1) |
| 标准错误 | stderr |
STDOUT_FILENO (即2) |
如果你觉得0,1,2在程序中看起来像一个幻数,可以使用STDIN_FILENO等宏定义来替代它们。
1 | |
子进程的标准输入、输出、错误的文件标识符和文件指针与一般文件一样,都继承自父进程。因此,对于被重定向的父进程,其产生的子进程也会被重定向至相同文件。
1 | |
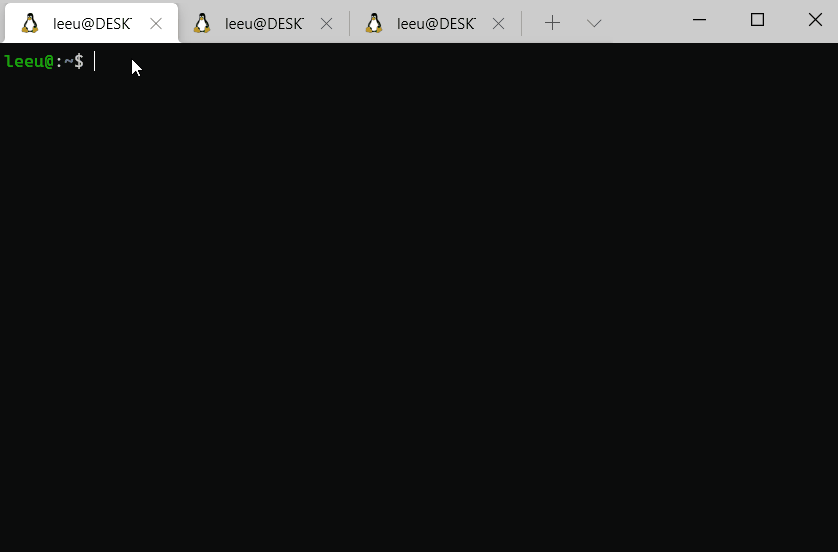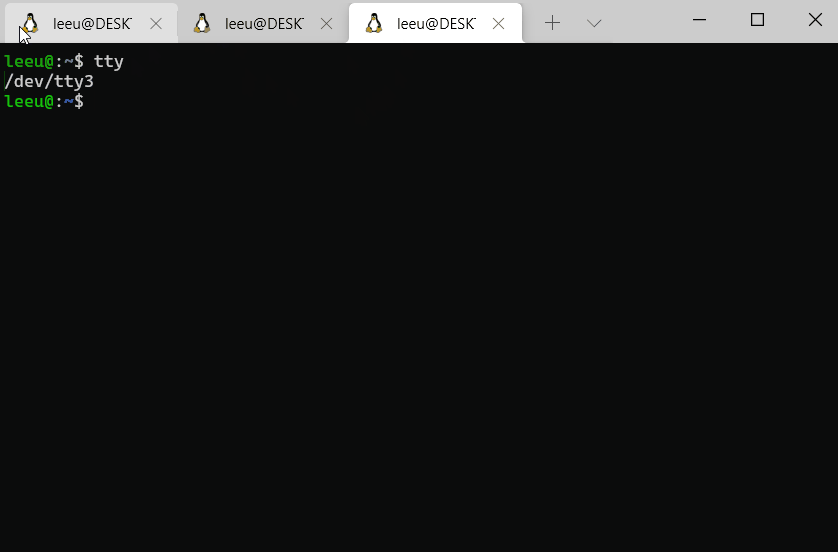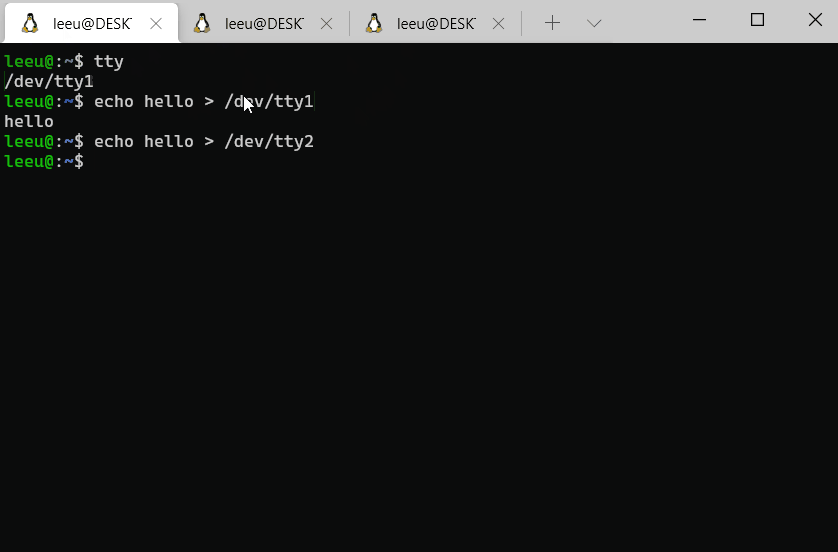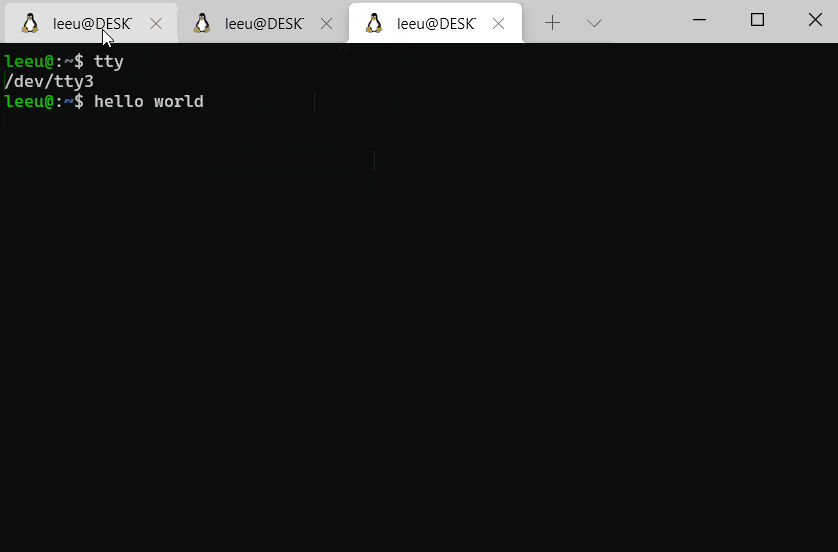
事实上,我很好奇操作系统是如何将标准输入、输出文件与终端界面、键盘进行连接的。这似乎与tty有关,我对此不太了解。大致来说是,在Linux系统中,控制台终端有一些设备特殊文件与之相关联,名如tty0、tty1、tty2等,可以通过shell命令tty命令显示终端机连接标准输入设备的文件具体名称,例如/dev/tty1等。
c语言中,int isatty(int fd)可以检测文件描述符fd所指向的文件是否为一终端机,char *ttyname(int fd)则返回fd对应的终端机文件名称。
可以用这种方式检验标准流是否被重定向。例如,如果isatty(STDOUT_FILENO) == 0,那么当前标准输出流被重定向。
1 | |
重定向
“标准”输入/输出的名称有许多种理解,在我看来,这个“标准”更多是“默认”的意思,它是每个进程默认具备的输入、输出方式,且默认指向了终端机上。如果是这样,我们也可以通过修改它来使得它看起来不再那么“标准”。
对终端的读写被抽象为了文件(tty文件),而0,1,2等标准输入输出的文件描述符又指向这些文件,因而构成了对终端的读写。然而,我们可以更改文件描述符的指向,让标准输入/输出不指向终端,而是某个文件,或者让其他文件描述符指向终端的输入、输出。
对标准输入/输出的重定向无异于对文件的重定向。
如果我们希望更改输入、输出的目标,对于我们可以控制的代码部分,将printf()全部替换成fprintf()就可以更改输入、输出流的指向文件(这太容易了)。然而,当我们需要执行其他程序,而这些程序又严格地使用标准输入输出时,就只能通过重定向的方式更改输入、输出的目标。具体而言,就是更改文件描述符0,1,2,或者是stdin,stdout,stderr所指向的文件。
就不罗嗦了,直接上代码。
1 | |
标准I/O风格
关闭stdout原先指向的文件(tty),然后令stdout指向我们指定的文件。也可以用freopen("1.out", "w", stdout);代替,这个操作OI选手应该不会陌生。
1 | |
系统I/O风格
将文件描述符0,1,2所指向的文件进行替换,即可实现标准流重定向。dup2(int oldfd, int newfd)将关闭newfd原先指向的文件,并将其指向oldfd所指向的文件,实现定向的文件标识符复制。
1 | |
希望对你有帮助!
下次写关于匿名管道。